


Taming the death over beast
A reinforcement learning based approach to ace the death over challenge

Test cricket is a miniature version of life, where you get to see the implications of every decision you take at a later stage. On similar lines, T20 cricket is probably a game of Who Wants to Be a Millionaire, where you get instant 'rewards' for your decisions. As the game goes on, the stakes of every decision increase, as is the case with death overs. Approaches are thus being explored to improve this decision-making, and one such approach is reinforcement learning.
Reinforcement Learning uses experiences to predict actions with the aim of maximizing the desired outcome. An example is its widespread use in recommendation systems on OTT platforms. I have chosen a very small subset of the problem it can potentially help solve in T20 cricket, which is recommending the best line and length to bowl to the batter in the death overs. I say this is a small subset because it can be extended to all phases of play if we observe good results. Also, line and length are not the only variables—there's pace, type of bowler, and game situation, all of which can influence these decisions.
UCB Algorithm
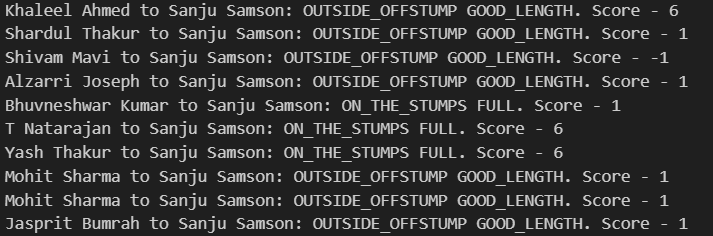
The UCB (Upper Confidence Bound) algorithm has two parts: the mean and the radius. The mean represents the average of rewards (runs) produced for each arm (line-length pair). The radius is a term that captures the confidence of the arm based on how many times it has been explored. More on the radius is explained later. Rewards were modeled according to the runs scored by the batter. I used the most efficient model after performing some parameter tuning. The model can also be altered based on priorities. For example, you may have a different reward model for a 'more wickets' algorithm compared to a 'more dots' algorithm. These algorithms can thus answer questions like -What line and length should Bumrah bowl to Klaasen to get him out? Or What is the best ball to bowl to Nicholas Pooran to prevent him from hitting boundaries? Currently, I have tried to balance both.
Why isn't a simple running mean approach good?
One simple approach could have been to just maintain the mean of rewards a batter got on every line and length. However, this doesn’t provide the best results because it doesn’t account for the 'exploration' aspect of each option. A line-length pair with a lower mean could still be risky if it hasn’t been tested or explored enough times. This is where the UCB algorithm helps. It includes a radius term along with the mean, which estimates the confidence in a line-length pair. Estimated mean and radius provide us a region in which the actual mean lies. A low radius indicates that the algorithm has high confidence in the estimated mean of the arm. Using UCB, therefore, provides more reliable predictions.
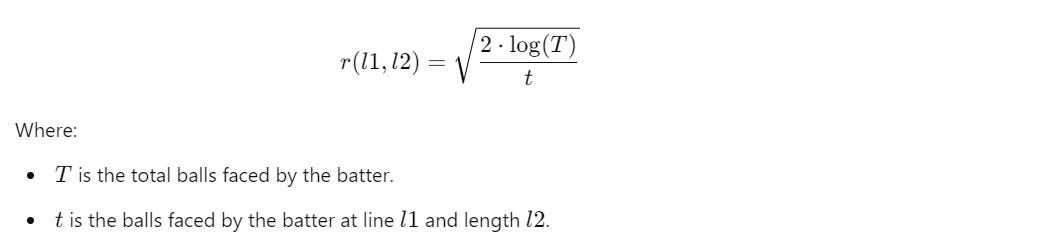

Experiments
Data prior to 2020 was used to initialize the mean and radius arrays for each batter. It was later tested on data post-2020 using three algorithms- Simple UCB, a hybrid UCB approach, and the running mean. At each step, parameters were updated, and an arm prediction was made using a weight parameter between the mean and radius. Lower values of both the mean and radius are preferable, as they indicate fewer runs scored and higher confidence, respectively. UCB outperforms the running mean algorithm and Hybrid UCB for both runs and wickets.



Future Work
Add more variables. Pace, bounce, and swing will provide a lot more information for a particular batter.
Try other UCB variants. With Simple UCB giving good results, it encourages us to improve further with other UCB-based algorithms. One variant (Hybrid UCB) was tested but did poorly compared to UCB.
Extend to all phases. Powerplay often decides the fate of the game. Hence a similar prediction algorithm for powerplay can improve decision making.